libreswan is now older than openswan was at the time of the forced rename to libreswan. Please stop using openswan. It is not safe to use!


libreswan is now older than openswan was at the time of the forced rename to libreswan. Please stop using openswan. It is not safe to use!
UPDATE: The police told us that anyone else who has been frauded by Ethan and did not get their money back, should call them at 416-888-2222 and ask to speak to the communications department.
I submitted a CAFC Fraud Reporting System, file number 2020-142083
Nov 27 update: Ethan is still actively committing fraud on kijiji. Additional listing and chat conversation added at the bottom of this post.
A few weeks ago a friend asked Naomi and me for some advise on getting a second hand macbook laptop. After looking around for a while, a nice deal came up a few days ago that was slightly cheaper than most laptops. Sold by what looks like some small computer shop called “9067388 Canada LTD”. And thus begins the saga of Ethan Sin, A.KA. Ethan Singam, A.K.A. GEETHAN VANNIYASINGAM.
(Note this posting has been updated to redact the friend’s name)
The Kijiji ad that started this all was finally taken down on Nov 19 during the day.
https://www.kijiji.ca/v-laptops/city-of-toronto/2016-macbook-air/1535479433




I told my friend that we would drive up to her and be there with her to pick it up at the Tim Hortons, just to ensure the Mac was working and we could get her Apple ID on it – to ensure it was not some stolen device. My friend called us an hour later saying the seller asked her to etransfer $40 to show that she was really going to show up, since he had other people offering to buy it as well. She asked if that was safe. Note that etransfers here in Canada are linked to your bank account. So unless you are going to take money and leave Canada forever, you are not going to mess around with that. She also by now had his phone number (289-600-9580), so if this was fraud, he would also be burning his phone number. A new SIM in canada is still like $15 or so. Plus, we had an email address to etransfer the money to, ethansingam@gmail.com
It seemed this was safe. And a real fraud would ask for more than $40 right? Also, this kijiji account was a few years old. Petty criminals aren’t in it for the long game. They don’t setup accounts to commit fraud years later. So my friend etransfered the $40.
A little while later, he informed my friend that he was going to be a little late. Something with picking up his mother. Meanwhile, we all drove up (in separate cars, there is a pandemic going on) to the Timmies up north. The guy was late. Very late. An hour and a few excuses later, still nothing. We guessed it was a fraud after all. Time to do some research.
What does the Canadian Chamber of Commerce know?
The company associated with the kijiji ad was founded in October 2014, and dissolved for “non-compliance” in August 2019. It was located at 19-13085 Yonge St suite 211 in Richmond Hill. Their latest filing shows the only directory is Yuri Nogaev residing at 2220 Lake Shore blvd Suite 1601 in Toronto. Yuri was also a director for another company “National Water Comfort LTD”:
https://www.companiesofcanada.com/company/995158-0/national-water-comfort-ltd
This company, located at the same address, was also dissolved by the government for non-compliance. This company has one other directory along with Yuri, GEETHAN VANNIYASINGAM.
That seems to match up nicely with the email address the etransfer was sent to, ethansingam@gmail.com. Some further investigation gives us Ethan’s current adventure, Ethan Advertising Incorporated, which still has a website at www.ethanadvertising.com. Note this company is claiming to sell branded tote bags and the above screenshot on the laptop showed someone working on “bag” things.
The website does not list an address for the company, only a contact phone number of 289-779-5556, which differs from the one Ethan gave my friend (289-600-9580). The domain registration is not very useful, as GoDaddy does not reveal much and places itself as proxy in between. We see a domain creation date of Jan 20, 2020.
Let’s pull up some corporate information. There is also Athena Management Services Inc:
https://opencorporates.com/companies/ca/8167168
But other than some old address information, no interesting new information. But then we found Ethan Advertising:
https://opencorporates.com/companies/ca/11843290
It links to the government registration:
https://www.ic.gc.ca/app/scr/cc/CorporationsCanada/fdrlCrpDtls.html?corpId=11843290
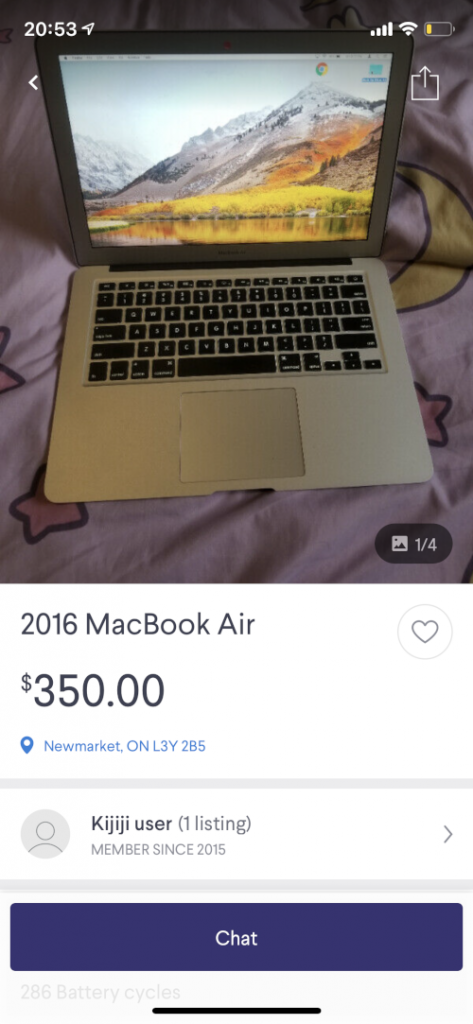
Which in turns gives us a new address: 946 Wildwood Dr, Newmarket ON L3Y 2B5, Canada. And this postal code matches the kijiji ad location! He must still be living there.
Although at this point it seems unlikely he actually owns the laptop he claims to want to sell. I mean, if you do this fraud, you would just grab a random laptop image from the internet and put up a fake ad….. Or would you? A reverse image search on Yandex didn’t give us a matching photo, and we don’t have much other data to investigate. Except, there is that laptop screenshot in the ad. If you look at the background you see it contains a folder what appears to be someone’s resume:

[updated to redact the name of the person on the resume. Let’s call this person “Friend”]
Let’s see if we can find [Friend]. It seems to be someone located in Toronto according to Facebook: [facebook url redacted]
The last thing this person did publicly was post an ad to sell some – familiar looking – Sailor Moon bed sheets. Let’s compare the photos:


No way! The same sheets and pillows are visible in the laptop photos of the kijiji ad. So the guy committing a kijiji fraud did not pick a random internet image, but somehow ended up using a local image? Perhaps it was [Friend] who sold the laptop and the sheets?
Naomi posted a comment to the facebook ad for the sheets with “Hi, do you know Ethan Singam“.
Since we had no indication she is related to Ethan, we decide to warn her and see if we could get a confirmation she sold that laptop ages ago by sending her a message.
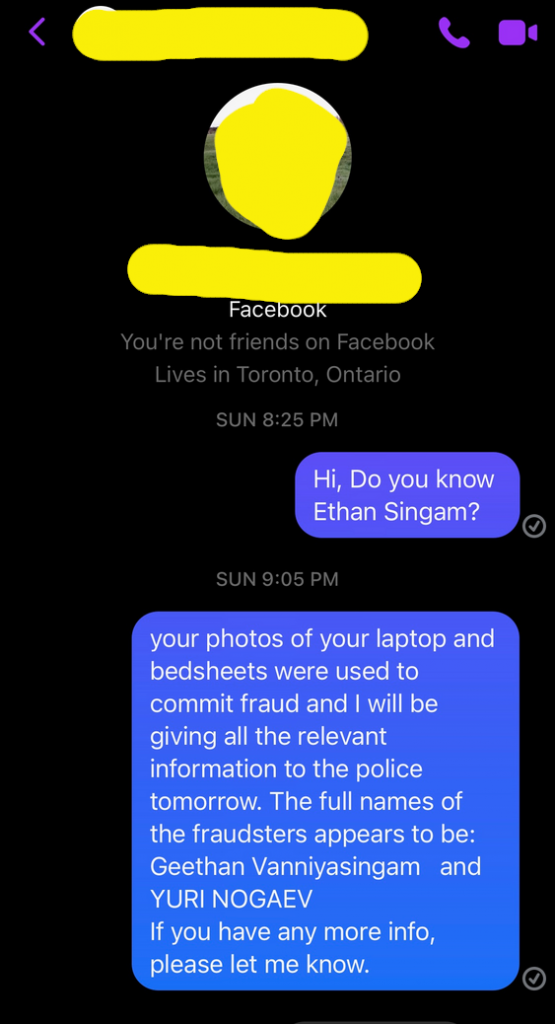
We did not get a response. But shortly after we sent the message, the bedsheets that had been listed for sale for a month suddenly vanished. If this had happened to me, I would at least have replied with something and not just silently removed my stale for-sale post. Even if just to ensure it doesn’t look like I’m cleaning up my posting linking me to this guy that is committing fraud.
My friend obviously send a text message telling him she wanted her money back, and not expecting any further messages. The next day she received:
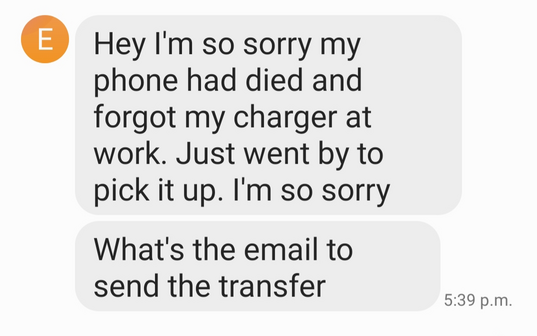
Seriously, the “I forgot my charger” excuse does not work anymore in a world where every phone is charged by Lightning or USB connector…
My friend did tell him her email address, even though he knows it as it is visible in the email interact transfer. So asking for the email address seems just a stalling tactic. Note that there is no word about the laptop sale. Perhaps he sold the laptop for more when someone offered more, or he decided to no longer sell it. But he doesn’t say anything like that. He is now just focused on returning the $40 without explanation of why his died phone prevented him from driving to the Tim Hortons. It’s as if there never was a laptop …..
He replies:
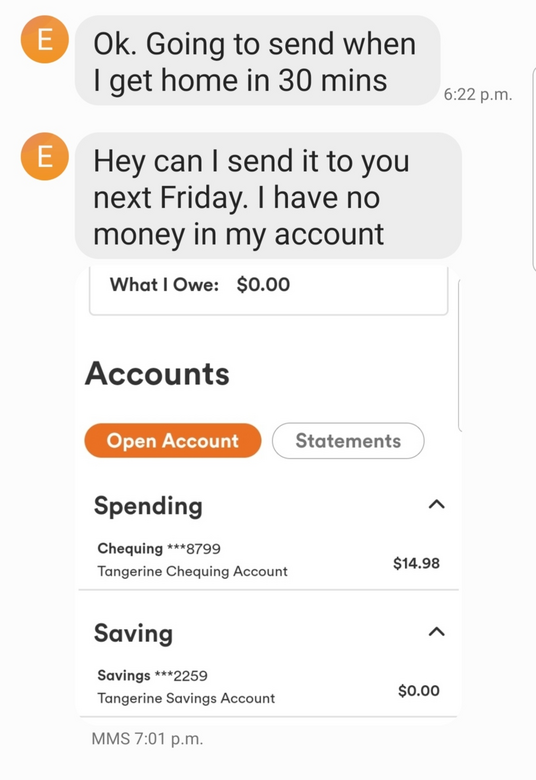
He must have already spent most of his $40 that he got only a day ago. Not a big saver. Sending money with a Tangerine account is free, so we asked him to send the $14 now and the rest later. We kind of wanted to see if we could get a confirmation of his identity via the financial transaction in case he really got concerned about his unwise scheme unfolding as it did. But we didn’t have high hopes. And sure enough:


We are fairly confident the $40 won’t get returned next Friday or the Friday after that. This was surely where the story would end. Except it didn’t. A day later Naomi noticed that she had received this message on Facebook:
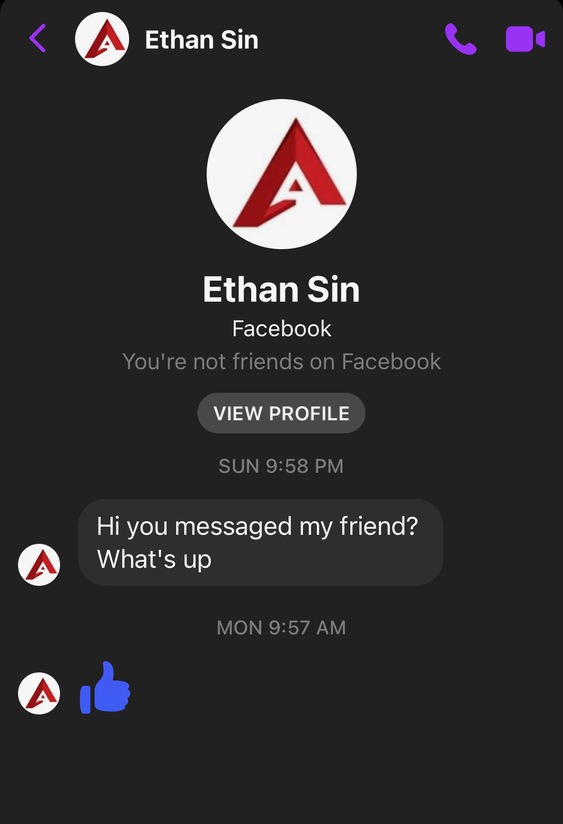
Look, this Ethan is using the same logo as Ethan Advertising. This account Ethan Sin was already active in 2018 and not just created for this response. Perhaps what happened was that [Friend] first saw the comment left by Naomi on the facebook ad for the sheets and reached out to Ethan, who replied right away to Naomi. Then [Friend] saw the message about fraud and quickly deleted the posting – and presumably told Ethan. But it was too late. He had already replied. And by contacting Naomi back, he confirmed Ethan, [Friend] and the laptop are all connected to each other.
I’m surprised the kijiji ad is still up. It has now been reported by my friend, by Naomi and by me as a fraud. Is he really making many times $40 on this fraud? Will he really pay the $40 back next Friday? Stay tuned! (it was taken down a day later)
UPDATE: Ethan did do this multiple times, Here is a link to a “Kijiji warning ad” from someone else who got scammed warning people about Ethan. If you got frauded, please feel free to contact me, paul@nohats.ca. !
UPDATE2: Combining the Facebook “read message” indicator timestamp with my server logs, we now know Ethan has read this blog post using his Rogers cell phone:
2607:fea8:560:3e00:7c83:a36c:388c:f195 – – [19/Nov/2020:11:43:38 -0500]
That should give the police another piece of information linking the person to the facebook account
UPDATE3: Ethan was contacted by [Friend] whom I gave a link to this posting and this prompted him to contact me to ask to take the post down or at leats the friend’s details. He ended up paying back the money he stole (well, $39.60 of it) so I redacted his friend’s details. He or Kijiji took down the fraud posting. Oddly enough, he included his conversation with [Friend] as a screenshot, showing [Friend] saying “I thought you already sold your laptop”.
So I guess he really put it up for sale, and then smelled an opportunity to get some more money. I don’t know how much he frauded people, but if he only did this twice, he could have gotten the same amount of money legally by properly pricing his laptop’s market value (which was defintely $80 lower than the commonly used price by other sellers.
Poorly executed crime doesn’t pay
So here it is, the repayment in all its glory, including the mixup of name and being $0.40 short:
UPDATE4: We now have heard of a third person that was frauded for $100 by Ethan who shared some screenshots with us:



November 27: Ethan is still doing his fraud scheme. This time as a different (old) kijiji account with no identifying name. And since he already pulled the listing, it’s hard to identify this account. The original kijiji posting was https://www.kijiji.ca/v-view-details.html?adId=1538151094





His typical “give me some money to reserve it” scheme on this entry submitted to me by another user who was smart and googled for the etransfer email address first (and found this blog post):
(UPDATE: Sevan Janiyan pointed out the Sun 2 was not a SPARC system)
Yesterday, Alec Muffet posted a few tweets regarding the Sun SPARC 2 bootloader’s DES routines.
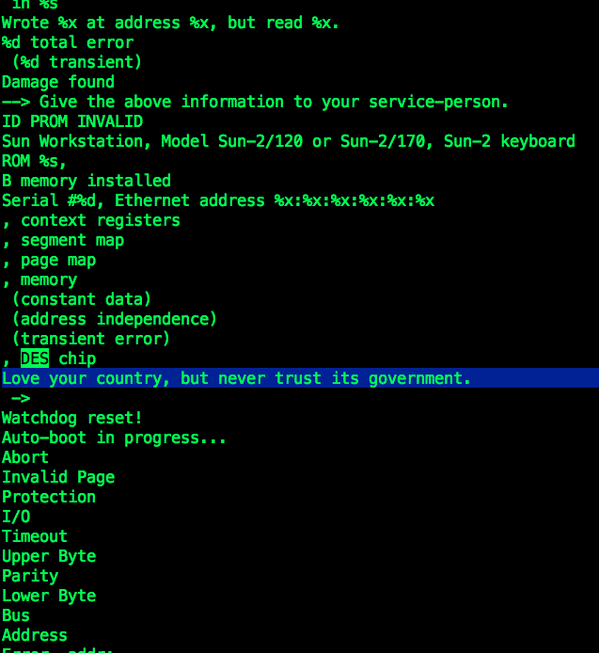
Alec figured that message was never supposed to be seen and suggested it was a kind of silent protest of someone in Sun against the US Government. I replied, saying I was pretty sure such a message anywhere in the Sun bootprom code must have originated by John Gilmore. So I asked John, and he did not disappoint. This is what I wrote me back:
> That must have been you? :)
Yes. Vinod Khosla, first President of Sun, came to me at one point
and said to put something hidden, triggered in an unexpected way, into
the ROM Monitor, so that if somebody cloned the Sun Workstation
(violating our software’s copyright), we could do that unexpected thing
to the competitor’s demo workstation at a trade show and thereby prove
that they had cloned it.The ROM Monitor command that printed “Love your country, but never
trust its government.” was “k2” followed by control-B and RETURN. (To
get to the ROM Monitor from the running Unix display, you had to hold
down the L1 key and hit “A” then release both; the monitor had special
code looking for that key sequence.) I had found that saying years
before on a hand-painted sign tacked up on a pole or tree in central
Pennsylvania, wrote it into one of my notebooks at the time, and
plucked it out as the hidden thing after Vinod asked. In the source
code it was obscured as a set of hex numbers, but in the binary it was
visible. (I didn’t bother to XOR it with something to make it more
hidden.)The circumstance Vinod was concerned about never did come about;
nobody stole the Sun boot roms. Early 680x0s didn’t come with a
standard MMU, so everybody who wanted virtual memory had to invent
their own, and our roms were very tied to our custom static-ram based
zero-wait-state MMU, which was also patented. A few companies
licensed the board design from us, like Imagen for a laser printer
controller, but they had a license to use the ROMs.The DES chip slot was intended to speed up DES for high security
networking applications, and we did get it working. I think Bill Joy
was the one who made it a part of the architecture, all the way
through the Sun-3, thinking that we’d use it as part of securing the
network file system. But the chip was expensive and
export-controlled, and our software never really used it (NFS ran in
plaintext and used the sender’s IP address for authentication!). So
it didn’t get stuffed on the production boards, and eventually they
stopped stuffing the support chips too. Tom Lyon wrote a nice device
driver for it, and a “des” user command that would use the chip for
file encryption if it existed (or fall back to software).
In one 68010 based model we also put in a slot for an Intel floating
point chip — I think the one that came with the 80286. We got it
working (I did the initial debugging) and fed it commands and
arguments via manual peek/poke in software. Doing that was somewhat
faster than the software floating point that we were otherwise using,
despite the overhead. But as I recall, Intel wouldn’t sell us the
chips in volume, because they didn’t want to make the 68000 more
competitive against their own x86 chips. So we had to wait til the
68020/68881 came out (Sun-3 era) before we had fast floating point.It’s nice that Matt Fredette made a Sun-2 emulator. I may have
images of old SunOS release tapes that might work in it. And I have a
Sun “FE Handbook” for the field engineers, that has a lot of the
details about what chips go where, what the jumpers on each board
mean, what the memory map of each board looks like, and etc.You can forward this info on to whoever…
John
I wrote an article over at the Red Hat Security blog about the SLOTH attack and IKE/IPsec.
So the weakdh.org article got some renewed press again, and it keeps coming up with this rather misleading paragraph:
We further estimate that an academic team can break a 768-bit prime and that a nation-state can break a 1024-bit prime. Breaking the single, most common 1024-bit prime used by web servers would allow passive eavesdropping on connections to 18% of the Top 1 Million HTTPS domains. A second prime would allow passive decryption of connections to 66% of VPN servers and 26% of SSH servers. A close reading of published NSA leaks shows that the agency’s attacks on VPNs are consistent with having achieved such a break.
That’s a rather bold statement. How do the authors know the MODP groups of 66% of VPN servers? This is what they write in their research paper:

We measured how IPsec VPNs use Diffie-Hellman in practice by scanning a 1% random sample of the public IPv4 address space for IKEv1 and IKEv2 (the protocols used to initiate an IPsec VPN connection) in May 2015. We used the ZMap UDP probe module to measure support for Oakley Groups 1 and 2 (two popular 768- and 1024-bit, built-in groups) and which group servers prefer. To test support for individual groups, we offered only the single group in question. To detect default behavior, we offered servers a variety of DH groups, with the lowest priority groups being Oakley Groups 1 and 2.
The first problem is that the first packet exchange performs the DiffieHellman and no IDs or credentials are sent. This means that the server in question does not yet know which configuration this connection maps to, unless it is limited by IP. If it is limited by IP, then their probe likely did not even solicit an answer because they came from the wrong IP – Cisco VPN servers tend to not give error messages and will just drop the packet. If the configuration is not limited by IP, because the connection supports roaming users, then the VPN server cannot yet reject the connection based on a weak MODP group. Imagine the following configuration (in SWAN ipsec.conf syntax):
conn regularusers
left=my.ip.address
right=%any
rightid=%fromcert
ike=aes256-sha1-modp1536
conn oldcisco
left=my.ip.address
right=%any
rightid="CN=knownweakdevice.com, O=OldVendor, C=CA"
ike=aes256-sha1-modp1024
When the weakdh people’s scanner showed up, it allowed the initial request/response packet to be 1024. But once it got further into the negotiation, if would authenticate and identify the remote peer, and refuse to establish the IKE connection with the modp1024 group for everyone except the one known buggy device. But since the scanner had no credentials, it never got that far. So this is a false positive. This is how freeswan and openswan worked, and how libreswan works. When it receives more information, it tries to switch connection to the best matching connection. Note that with only the above two configurations enabled, libreswan would immediately reject an incoming IKE exchange that tries to use modp768 or modp2048, since no loaded connection specifies that modp group. Note the default when not specifying an IKE line is modp2048 and modp1536 for IKEv2, and modp1536 and modp1024 for IKEv1. With a preference for the higher group.
This method of connection switching requires the IKE daemon to know or go through all the connections to look at the modp group. If I understood the strongswan implementation correctly, it does not even bother to reject the incoming request based on modp group. It will just answer whatever the modp group is on the first packet. Later on in the exchange, once it has committed to a specific configuration, it will check for the modp group and reject the connection. So that is false positive number two for the scanner.
The article continues:
Of the 80K hosts that responded with a valid IKE packet, 44.2% were willing to accept an offered proposal from at least one scan. The majority of the remaining hosts responded with a NO-PROPOSAL-CHOSEN message regardless of our proposal. Many of these may be site-to-site VPNs that reject our source address. We consider these hosts “unprofiled” and omit them from the results here.
Well, that means the authors just excluded all freeswan/openswan/libreswan servers that are configured to not allow modp1024 because that is exactly what they would return. Libreswan per default does not allow modp1024 in IKEv2, so this is a rather big false negative!
We found that 31.8% of IKEv1 and 19.7% of IKEv2 servers support Oakley Group 1 (768-bit)
In our sample of IKEv1 servers, 2.6% of profiled servers preferred the 768-bit Oakley Group 1
Now regardless of the strong connections the authors missed, they did find a large number of weak ones. There is no excuse whatsoever for an IKEv2 server to allow modp768 or modp1024. It’s even questionable to allow modp1536 because every IKEv2 implementation supports modp2048. The 31.8% of modp768 is also inexcusable. The freeswan/openswan implementations never supported modp768 unless you specifically recompiled it (and the distro versions never had it compiled in). libreswan removed the compile time option altogether. The modp1536 group made it into freeswan – and preferred over modp1024 – before the modp1536 group was actually standardized in an RFC! So unless you specifically configured any of the *swan IKE implementations to use these weak groups, and your remote clients didn’t start out with a weak group, you would be using modp1536. Even back in 1997. This has not been an IKE problem in opensource IKE software ever. But, there is a catch.
The insecure Cisco administrator
86.1% and 91.0% respectively supported Oakley Group 2 (1024-bit)
This statistic matches my 15 year experience with IKE very well. It is very unfortunate that administrators fear reconfiguring a Cisco’s IPsec configuration. As such, when you need to interop with a Cisco, the other party usually has a SOP document that tells them how to configure the Cisco for use with 3DES-SHA1 modp1024. You are lucky if you are not forced to use md5. This is not a technical problem – Cisco VPN Concentrators can do modp2048. It is the humans that are afraid to touch something they are not familiar with that works.
MODP groups in the near future
The ipsecme working group at the IETF is actually working right now to update the set of mandatory to implement algorithms. This also includes promoting new algorithms to SHOULD or MUST and demoting others to MAY or MUST NOT. But it will only do so for the IKEv2 protocol. Most vendors have locked their IKEv1 stacks and will not make any changes to it anymore. So IKEv1 will always stay using modp1024 and modp1536. So if you can, use IKEv2.
Conclusion
The 66% of VPN number is surely very wrong. Measuring that number is per definition impossible, due to the common implementations of IKE daemons that hide the acceptance and rejection of the modp groups from un-authenticated IKE clients. However, I do agree that there are too many old IKE servers deployed that need to have their configurations upgraded to allow stronger modp groups and stronger encryption protocols.
If you want to go beyond modp1536, you should really upgrade to IKEv2. You will also need to move to IKEv2 if you want to move from AES-SHA1 to AES_GCM (or soon chacha20poly1305). Any IKE implementation that does not support IKEv2 is not actively maintained and should not be used.
See also my earlier article weak DH and LogJam attack impact on IKE
UPDATE: A more detailed explanation of the NO_PROPOSAL_CHOSEN case
The way IKE is specified and the way it works in practice is slightly different. The theory of operation is that a client starts with a list of proposals, that can include multiple DH modp groups. But that initial packet already contains the KE payload for one of the DH modp groups. So the client might send a proposal set containing 1024 + 1536 + 2048, but it only sends one KE payload. That KE payload basically denotes the client’s default. In this example, that would be either 1024 or 1536 or 2048. If the server receives this KE + proposal, it needs to make a decision. If the KE modp group is acceptable, use that. If not, then look if the proposal contains any other modp groups it is willing to use. If it does, it should return INVALID_KE with a payload of the acceptable modp group to use. The client receiving this can then select the other modp group it is willing to use and start the IKE exchange from scratch with a new request. (It’s a little more complicated because this reply is unauthenticated, so the client might wait for a bit to see if a “real server” accepts its modp). In practise, this often does not work. For example iphone ios8/ios9 do not process INVALID_KE payloads at all, as they assume a single correct modp group is configured on both sides using their enrollment program. So in practise, the server will accept the client’s DH if it is one of its allowed groups. This can mean that even though client and server both can do a more secure DH group, they end up using the most commonly used shared group. This is usually 1536 or 1024 for IKEv1 and 2048 for IKEv2.
An additional issue with IKEv1 is that the first packet also contains the OAKLEY_AUTHENTICATION_METHOD. If this is mismatched (eg PSK vs RSA) the IKE server will also return NO_PROPOSAL_CHOSEN.
And both both IKEv1 and IKEv2, the initial packet contains encryption/integrity algorithms too. If these mismatch (eg AES vs 3DES or SHA1 vs MD5) then the IKE server will also return NO_PROPOSAL_CHOSEN.
You can test the NO_PROPOSAL_CHOSEN return directed at vpn.nohats.ca. It is configured to accept connections from anyone, but requires modp1536 for either IKEv1 or IKEv2, using X.509/RSA authentication. You can send it PSK requests for modp1024 and get NO_PROPOSAL_CHOSEN.
A large dutch ISP ran into issues with their Registrar Network Solutions over the weekend. (why anyone would be using NetworkSolutions like it is 1993 is beyond me)
A misunderstanding over a payment caused hundreds of domains to be entered into PENDING-DELETE state. One such example is puiterwijk.org. Some of these domains have been in this state now for days.
What made things worse is that said NetworkSolutions took over running DNS for these domains, including an MX record that points to an actual mail server!
So if you were lucky, your email just bounced. If unlucky, someone else got your emails. The TLS certificate on that mail server doesn’t even match their hostname, so anyone on path can also just MITM it and a traceroute shows 26+ hops all over the place.
However, they did not modify the DS records after taking over the NS records and MX/A records. So those domains that used DNSSEC, including the above mentioned puiterwijk.org, are not resolving at all because the validators are rejecting the NetworkSolutions stolen DNS zones as bogus. So, my emails to this person were not delivered to the rogue MX servers because both he and I deployed DNSSEC. Hoorah, I guess….
Now, taking over MX and causing email failures like this is pretty evil. I would hope this violates some ICANN or PIR agreement but as said Registrar has been a sad registrar since uhm about 1993, I guess nothing is going to change. Let’s hope the Dutch ISP has learned from this and will move to another Registrar soon after this mess gets resolved.
TL;DR The LogJam downgrade attack does not apply to MODP groups in the IKE protocol, only to TLS, so IKE or IPsec is not impacted.
If you are using libreswan you are not vulnerable to weak MODP groups and using MODP2048 per default unless specifically configured for a lower MODP group.
If you are using openswan with IKEv2 you are using MODP2048, but if you are using IKEv1 you are using MODP1536 which is still much stronger than MODP768 or MODP1024.Libreswan as a client to a weak server will allow MODP1024 in IKEv1 as the least secure option, and MODP1536 in IKEv2 as the least secure option.
Openswan does not properly implement INVALID_KE, so it cannot connect to another DH group than the one it started out as, so it runs the risk of getting locked out if the server side bumps their minimum MODP group to 2048. openswan defaults to MODP1536 in IKEv1 and MODP2048 in IKEv2
(minor update: Hugh Redelmeier corrected me that freeswan never supported modp768 – the smallest modp was 1024)
A bunch of smart crypto research released a paper describing the LogJam attack. It is a cryptographic attack on weak DiffieHellman groups. It talks about DH in various protocols. It is an interesting read. When you break the DH layer, you obtain the secret session keys needed to decrypt the various protocol (TLS, IPsec, SSH, etc) sessions. The conclusion from the paper is that any DH group smaller than 1024 should not be used as even non-nationstate attackers can obtain the resources needed to break these. They further conclude that they believe it very likely that the standarized 1024 bit DH MODP group has been broken as well by the NSA. It involves large scale computing clusters and sieving and doing a lot of heating up the planet. They can do this because in crypto standards, everyone uses the same MODP prime values for the DH exchange.
First, a small clarification. When the paper talks about IPsec, they mostly mean the IKE keying protocol, not the ESP packet encryption protocol. IKE is responsible for the secure keying operation that generates symmetric session keys used for the actual packet encryption in the ESP protocol. IKE is the userland daemon, ESP is the kernel level encryption/decryption.
The DH values for IKE are listed in various RFC’s, and can be found in the IANA registry for the older (but more used) IKEv1 GROUP values and for the newer but less used IKEv2 GROUP values. For the published attack, the only type of groups relevant are the MODP groups. The ECP groups do not use exponentiation and thus are not vulnerable to factoring primes.
IKEv1 MODP groups
In IKEv1, the most common modp groups are modp1024 (DH2) and modp1536 (DH5). Some people still want to use modp768 (DH1) but it has strongly decreased over time. Most IKEv1 stacks also support modp2048 (DH14) up to modp8192 (DH18) although notably Cisco administrators in general seem to have stuck with modp1024 and modp1536, just as they have stuck with 3DES and MD5/SHA1. This is mostly because the technical knowledge to configure Cisco’s for VPN is so difficult, that once a Standard Operating Procedure(SOP) is in place, no one wants to, or is allowed to, modify the configuration used. (It’s also the tail end of Cisco asking for extra money to support AES many years ago)
FreeS/WAN never supported modp768 – John Gilmore had good ideas about scaling and NSA computing powers, he was one of the people behind Deep Crack, the EFF 1DES cracker. Openswan which was forked from FreeS/WAN in 2003 had support for modp768 (and 1DES) but did not compile it in per default and neither did any of the Linux distributions that shipped it. But people needed it frequently enough to interoperate that the code was added, but disabled per default. Notably, embedded people using the *swan’s would enable it due to customer demand. It annoyed us so much that sometime around 2005 (I can’t find it in the changelog) we just ripped it out. Of course, it did not prevent people from patching it back in, which some did. Most likely, many unattended embedded devices out there are still doing modp768 bassed VPNs, and as LogJammer shows, that’s within reach of academia and banana republics – so count on these being decrypted routinely by the Five Eyes, Russia, China, and probably most other Western TLA’s.
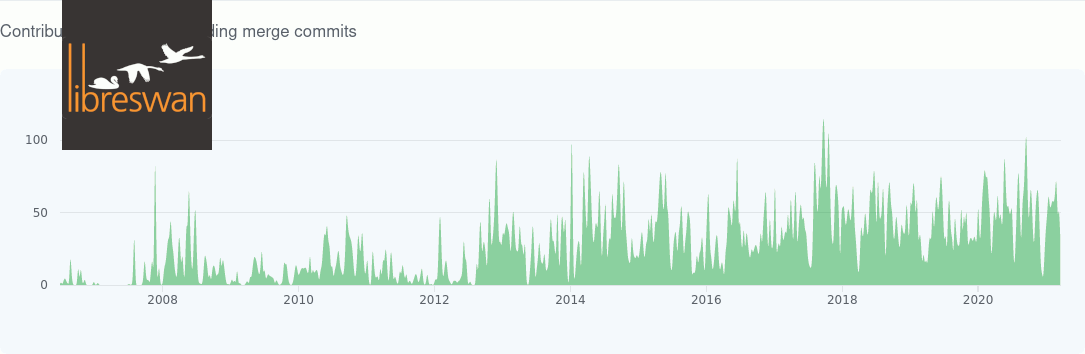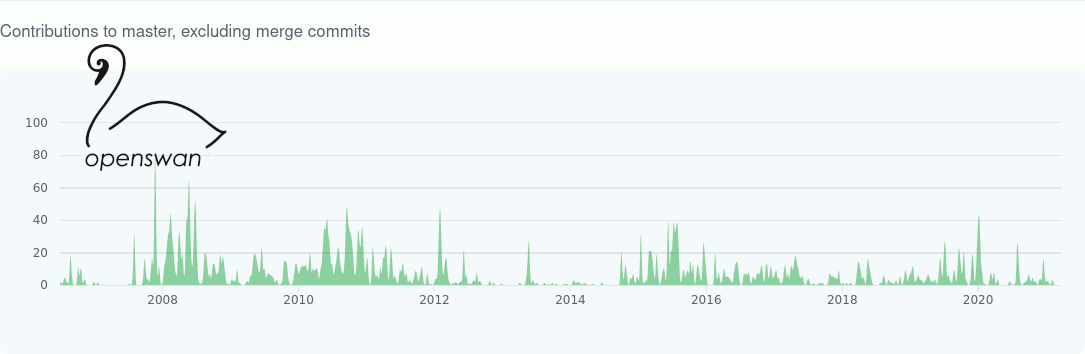
The default IKEv1 modp group for openswan (and libreswan) was 1536. In July 2014, libreswan changed this to MODP2048. I believe openswan is still using modp1536 (and if you are still using openswan, I recommend that you switch ASAP, see this git commit activity comparison
IKEv2 MODP groups
IKEv2 has seen a very very slow start. I’ve only seen it really being deployed in the last two to three years. Most of these deployments use at least MODP2048, do not support MODP768, but are usually willing to do MODP1536 or even MODP1024. The latter is mostly done for fear of compatibility issues. But also to support an upgrade path for all devices. If your VPN connection supports “either IKEv1 or IKEv2” and your clients are still connecting with IKEv1, then most surely you will need to support MODP1536 and even MODP1024, or you will be losing your older VPN clients.
In April of 2008, as the then release manager of Openswan, we released version 2.6.12 which changed the IKEv2 default to MODP2048. This was a controversial decision – one developer quit the openswan project over this change because he deemed it would cause too many interoperability failures because many IKE implementations did not properly implement INVALID_KE renegotiation or simply did not support MODP2048. No problems emerged after the change, but most likely because simply no one but the certification checkbox people were even testing or running IKEv2 at the time. Since then, libreswan (but not openswan) has implemented proper INVALID_KE renegotiation.
RFC 5114 MODP groups
There is a semi-mysterious
The purpose of this document is to provide the parameters and test
data for eight additional groups, in a format consistent with existing RFCs.
It lists one new 1024 bit MODP group and two 2048 bit MODP groups, when we already had RFC 3526, which has MODP groups up to 8192 bit. The odd thing is that when I talked to people in the IPsec community, no one really knew why this document was started. Nothing triggered this document, no one really wanted these, but no one really objected to it either, so the document (originating from Defense contractor BBN) made it to RFC status. Due to this strange history, the RFC 5114 MODP groups are not included in any default proposal set and MUST be manually configured before libreswan will use these groups. We had to support these groups due to demands for RFC compliance and certifications.
IKE and IPsec are not that bad you know
Not that I want to go into a nahnahnahnahnahnah mode, but to those people that keep dissing IKE and IPsec, note that we were again not vulnerable unlike TLS. And when it comes down to cipher mode attacks, IKE has proven to be far more secure than TLS has been in the last three years. So please stop beating up on IKE/IPsec citing some old papers from the late 90’s. Kthanks
I’m sad to hear Terry Pratchett has died. I would write “it is not fair” in all caps, but that might get misinterpreted.
I had the pleasure of meeting Terry Pratchett at a book signing in The Netherlands when “The Last Continent” was released. I was getting the book for an Australian friend of mine whom I was about to visit in Australia. She had told me she refused to read Pratchett because all her friends read his books and he was just “too mainstream”. I told Terry this at the book signing when handing him The Last Continent. He thought for a moment and wrote “Carol, Don’t read this one either”.
I greatly enjoyed his books, but also at the time in the late nineties, his postings on Usenet in alt.fan.pratchett. He was the first celebrity that I saw that talked to his fans without a publisher in between. You got to talk to the real Terry. Of course, a lot of talk on alt.fan.pratchett was about whether or not that was really Terry Pratchett. You could tell from the writing though. It was him.
Below are some of the quotes I saved from alt.fan.pratchett, hopefully someone can grab the entire usenet archive from Google before it is lost forever……
on Cuba
I would like to confess that I know my books have been read by a Cuban. At least, I think he is Cuban. Certainly he’s got Cuban relatives. Or knows someone from Cuba. Or knows someone who smokes cigars, at least.
I realise this may put the upcoming US tour in jeopardy, and throw myself on the mercy of the courts.
On the use of IMHO
Oh, as a naturally democratic man I use the simple and common net usuage; it means ‘In my pompous and unwarranted opinion as a person who, despite an apparent intelligence level somewhere between that of a clam and a line-dancer, won’t hesitate to pronounce definitively on any damn subject under the sun.’ Of course, I might have got it wrong. It was just based on long observation:-)
On a hedge
You’ve got to remember that no hedge is ‘natural’; the whole point of cutting and laying the traditional quickthorn is to make a living barrier that even a sex-crazed ram isn’t going to be able to push through.
On Tomb Raider
> Same here, maybe I’d like her more if she didn’t look like she was made of plastic.
Never mind about Lara. The Tomb Raider games are the only games where I’ve shot someone because they were getting in the way of the scenery. Who will forget the brown trousers moment with the T-Rex in TR1? And in TR2 I spent some time driving the snomobile and the boat just for the sheer heck of it…
On Doom
“Over the centuries, mankind has tried many ways of combating the forces of evil…prayer, fasting, good works and so on. Up until Doom, no one seemed to have thought about the double-barrel shotgun. Eat leaden death, demon…
On Doom at a con in NZ
At a con in NZ they had a number of machines hooked up and four kids were playing Doom in co-operative mode with the superb Aliens-TC patch, which was incredible well done. They were advancing through the nest, and I explained to them that the only way they’d survive was with some sense of military discipline. Hah, they obviously thought, was does *he* know?
Whereupon an alien stepped out of the corridor wall behind them.
Whereupon they all turned around and fired like Hudson on speed…
Whereupon the guy who had been at the *front* of the line shot all three of his colleages who had been in single file behind him…
…whereupon the alien ate him.
On receiving emails from fans
But in reality people often aren’t writing because they want that information. They want to write an email to a favourite author, and they don’t want to sound too fanboy, so asking a real question gives them, they feel, a reason. This is fine. It’s just that there’s so many :-)
About people posting ideas for DiscWorld in alt.fan.pratchett
You tell *me* what to do, folks. My view is that a) I’m not intending to nick anyone’s suggestions b) I’m not intending to quit reading afp c) if there are ever problems, I can afford really expensive lawyers:-)
On vampire ideas
> I am talking about the carefree use of informal language such as “nicked”,
> “stolen”, even “plagiarised”, and of course the ever popular “it is clearly
> obvious that…”, when referring to things which are, in the end, usually
> entirely unconfirmed references or resonances we *think* we may have
> spotted in PTerry’s work.
A sort of moderating comment…(but best to add some spoiler space)
Probably no other fictional monster has been so written up, filmed and played as The Vampire. I read my way through a shelf of stuff while writing CJ and *of course* there are scattered through it references to the general vampire mythos — as I’ve said elsewhere, there’s little in there about vampires that I had to make up. Vampires didn’t begin and end with Dracula. There were even high-class, Lestat-type vampires in 19th Century fiction. There are *lots* of references in CJ to ‘Dracula’, both the original book and the various influential movies that have been made of it, because they’ve largely defined our image of the vampire (which, before ‘Dracula’, was quite different). And it wouldn’t be DW if I couldn’t take the pi– poke some fun at the Anne Rice wannabes who think vampires are so cool…
Of course, everyone in Transylvania — oops, Uberwald — has a servant called Igor. It’s practically compulsory. Does Igor show Count Duckula a picture gallery anywhere in the series? I don’t know, and I don’t care much — because I can recall ‘pictures of ancestors’ as minor background in vampire movies generally (sometimes the eyes move, and sometimes, ‘hey, did you know you look *just* like the girl who died 300 years ago and here’s her picture?’ Generally, of course, the vampire in the pictures always looks remarkably like the one doing the showing…) And I can’t quite bring myself to believe that ancient retainers grumbling that the new people aren’t a patch on the masters he used to have was invented by Cosgrove-Hall.
I can hardly object to annotations, but I did spend my youthful Satuday mornings watching endless bad (and good) vampire movies (it got so I could *recognise* that bit of road by the dark lake where, in Hammer Horror movies, the coach *always* loses a wheel) and before I wrote CJ I read of lot of historical and reference vampire stuff (as have most modern writers of fictional vampires). We all mine from the same seam. That’s why most vampire movies are remarkably similar — the only suspense is working out which *new* way of killing a vampire is going to be demonstrated this time.
Today, Laura Poitras and Jake Appelbaum spoke at the 31C3 conference and in collaboration with Der Spiegel published an interesting article on VPN exploitation by the NSA.
The “TL;DR” summary of what follows below is: If you configure your IPsec based VPN properly, you are not affected. Always use Perfect Forward Secrecy (“pfs=yes” wich is the default in libreswan IPsec) and avoid PreSharedKeys (authby=secret which is not the default in libreswan IPsec). If you really need to use PSK, use a strong shared secret that cannot be brute forced. The NSA has their own version of IKEcrack running on millions of dollars worth of CPU’s. Also, the NSA sneaks into your router to steal your PSK’s so they can decrypt all your traffic.
Update 1: from media-35513.pdf (“TURMOIL/APEX/APEX High Level Description Document”):
CES generally requires the packets from both sides of an IKE exchange and knowledge of the associated pre-shared key (PSK) in order to have a chance of recovering a key for the corresponding cipher (ESP). A major goal of APEX is to access two sides of key exchanges of traffic of interest”
Update 2: To stop the NSA HappyDance, I just commited code to libreswan IPsec to warn about weak PSKs with a message notifying the sysadmin that as of July 1st, 2015, libreswan will refuse those weak PSKs. To determine the strength of the PSK, I used the Shannon Entropy value. If the PSK has a Shannon Entropy of less than 3.5, a warning will sound and in 6 months it will refuse to use that PSK.
Update 3: Just to make it clear – To break IKE PSKs, you first need to break the initial DiffieHellman exchange, which is usually MODP1024 or MODP1536 in the bad cases (and MODP2048+ in the good cases). The exception to this is IKEv1 Aggressive Mode, where the MAC computed with the PSK as secret key is sent
in the clear. As a result one can mount an offline dictionary attack.
IPsec is not IKE
First, let’s clarify things a little bit. Although everyone is talking about breaking IPsec, what they really mean is breaking the Internet Key Exchange (IKE) that is used to negotiate and create symmetric keys that are used with IPsec for encryption and decryption. IPsec itself can use various ciphers and algorithms. It can use a separate encryption (AES, CAMELLIA, SERPENT, TWOFISH, 3DES, etc) + integrity (SHA2, SHA1, AES_XCBC, MD5, etc) mode or it can use an AEAD cipher that combines these two into one (AES GCM, AES CCM, CAMELLIA GCM, etc)
But Jake said to stop using IPsec
None of what was said by Jake or published by Der Spiegel shows any attack on these ciphers or algorithms. Even the MD5 use within IPsec (HMAC-MD5) is not as weak as people usually believe it to be by confusing it with non-hmac use of MD5. The comments Jake made and the material in the published slides show attacks against weak IKE configurations, router compromises, and possibly against some IPsec hardware accelerators. Below are my comments on those slides that are interesting in the context of IKE and IPsec.

The focus of the VPN decryption team lies with IPsec and SSH. I think that fits the deployment. These two protocols are the most widely used encryption protocols to transfer bulk data. While the hacker community might focus on OpenVPN, that’s not where the real deployment is. The mention of PPTP is curious. From what I see, PPTP is basically dead as a VPN technology, although it is still widely used in Russia as an encapsulation technique for ISPs to connect endusers. It’s probably just listed there for intercept because it is so trivial to do, you might as well gather it.
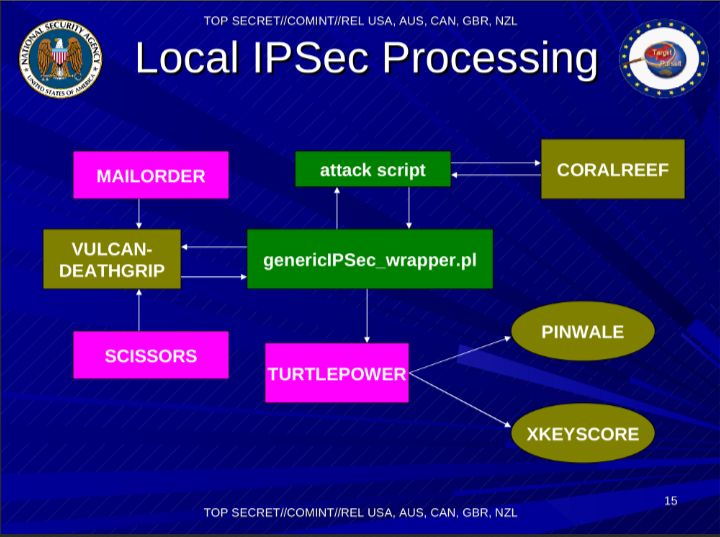
This slide is harder to make sense of. I think that here the NSA is talking about IKE and IPsec combined, although they call it IPsec. Perhaps once they decrypt traffic, it goes into XKEYSCORE? They don’t seem to use XKEYSCORE as an input to crack the IKE PSKs? I’m amused by the name VULCAN-DEATHGRIP which might indicate that the HiFN (now Exar) Vulcan IPsec accelerator card might have a flaw in it that allows them to decrypt those IPsec VPNs. Also, I hope they properly mask their perl scripts for malicious decrypted traffic :P

This is probably the most interesting slide. It basically states that IPsec VPNs are compromised by router compromises that steal the IKE PSKs. This might be a good time to upgrade your router firmware to the latest version, and change to new strong PSKs (or switch it over to RSA 2048+ instead)
The AppID refers to the XKEYSCORE signature name. I’m glad to see that IKEv2 is finally catching on, even within the NSA :)

This slide is mentioning IPsec scripts, which might refer back to the previously mentioned genericIPSec_wrapper.pl script. This clearly indicates an IKE PSK brute force decrypting engine. If you are using weak PSKs, the NSA is decrypting your IKE traffic which will give them the keys to decrypt your IPsec traffic. Enabling PFS will help you a bit, but ultimtely you should really just switch to using RSA (or ECP) authentication and skip PSK’s alltogether. Note that the FIPS standard already disallows using PSK’s for IKE/IPsec. The NSA knows it is just too dangerous and weak.
Note to the NSA, please see RFC 4301 Section 1.1 which states:
The spelling “IPsec” is preferred and used throughout this and all related IPsec standards. All other capitalizations of IPsec (e.g., IPSEC, IPSec, ipsec) are deprecated.
On slide 31 it states: IPSec: 6640 (protocols) and 6648 (ports)
I don’t know what that refers to. Possible backhaul transport ports or part of an API port ?
On slide 33 it states: Need all the pieces (IKE and ESP for IPSec)
This really shows that the NSA is breaking IPsec by breaking IKE, which mostly seems to come down to weak PSKs and no PFS. And again, in case you still did not get it on slide 39:

“TAO got the configuration files which provided us the PSKs to enable passive exploitation”
So your IPsec VPN is getting owned because your VPN gateway got owned! Run your VPN on a dedicated machine, preferably opensource, and lock remote access via ssh down using strong keys and IP filtering.
And the last interesting nugget is on page 40:

“NSP had an implant which allows passive exploitation with just ESP”.
I read this to mean that the hardware or software of the system running IPsec was compromised, causing it to send valid protocol ESP packets, but creating those in such a way that these could be decrypted without knowing the ESP session keys (from IKE). Possibly by subverting the hardware number generator, or functions related to IV / ICV’s / nonces that would appear to be random but were not. Or less likely if the hardware/software was using padding bytes to reveal decryption keys.
Conclusion
If anything, I would say that IPsec and IKE have withstood the attacks of the NSA. The fact that the NSA needs implants and needs to use brutce force attacks against IKE PSKs shows that despite its kitchen sink nature, IKE and IPsec are doing quite well if you configure it properly and run it on a secure host. But misconfiguration of IKE is something we did a poor job of preventing. We can and should have more automatic IKE/IPsec deployed using strong default configurations.
And you should hear back from The Libreswan Team in the next two months regarding just that. Opportunistic Encryption: Round Two
It’s easy to forward or like an article of which the title says something you agree with, without actually reading the content. It seems “DNSSEC has failed” is one of those that showed up in my twitter feed. It’s so defunct of facts, it’s pretty clear most people have just read the title and retweeted it. Hopefully, they will at least read this post before not retweeting it.
It starts comparing the DNSSEC protocol with the SSH protocol. It claims ssh just works. It fails to take into consideration that the two are completely different trust models. With ssh, you tend to own both end points. So there is no issue of PKI or key distribution or trust. And even so, I am willing to bet the author never actually checks his SSH fingerprints when connecting to new servers, and just depends on the ssh leap of faith. Well, security is easy when you can assume you are not under attack. Most ironically, the easiest and only cross-trust-domain SSH public key distribution system out there is the DNSSEC protected SSHFP record. The only other one I know of is GSSAPI and other hooks into centrally-managed systems – eg all systems under one administrative control. Trust is pretty easy when you centrally distribute trust anchors.
Let’s also not talk about the debian ssh disaster, which was a pretty spectacular failure compromising thousands of ssh servers. Let me conclude the ssh comparison with inviting the author to login to bofh.nohats.ca using ssh in a fully trusted matter. He will end up 1) calling me to verify the ssh host key, 2) trusting the SSHFP key in DNSSEC or 3) leap-of-faithing it and hoping he was not under attack.
Next, the author brings up the tremendously easy to use and success of TLS. Never mind that we still need to run SSL 2.x for WinXP compatibility, most servers run TLS 1.0 which is severely broken, we just had the TLS 1.2 resumption/renegotiation disaster, about 4 CA compromises in 2013, and browsers running to patchwork solutions like hardcoded certificate pinning and Certificate Transparency registries that uses “n of m” style “it is probably the right certificate” solutions. There are about 600 (sub)CA’s that can sign any TLS certificate for any domain on the planet, ranging from Russia, to Iran to the U.S – all parties that are known to coerce parties and with a heavy industrial espionage component.
If TLS was successful, port 80 would be dead. Port 80 is the proof that the TLS trust model has failed. It involves money and so these certifications are only available to corporations. While DV certificates are now basically free, they are also considered worthless (protection against passive attack only) EV certificates are now dropping in price – which will make them finally available for more people but unfortunately because of that also lose their value. And all of this security hinges on the (mostly hidden) CABforum and browser vendor decisions on which CAs to include, and which CAs not to include.
While on most proprietary OSes, these preloaded CAs are at least managed by the vendor, the situation in Linux is a disaster. OpenSSL doesn’t support blacklists, NSS does. GnuTLS I don’t even know. Where are these CAs and blacklists? Do you know applications using openssl for their TLS are using the same CA bundle as applications using NSS or GnuTLS? Only very recently has Fedora and RHEL moved to a system where this is guaranteed. Even worse, most python wrappers using TLS don’t even check anything of your TLS connection. Presenting the wrong certificate will just cause that software to continue. And then look at the latest Apple TLS bug where anyone could bypass all TLS checks completely. How the author can even point to TLS as a security success is a complete mystery to me. It’s the worst computer security disaster we ever created! Look at the amount of complete failure TLS deployments at SSL Pulse – 30% allows weak ciphers, 6% has a broken certificate chain, less then 30% supports TLS 1.2, 6% vulnerable to the renegotiation/resumption attack, 70% vulnerable to the BEAST attack, 13% vulnerable to the compression attack, 56% allow RC4 and 50% does not support PFS. And that according to the author is the “success” that DNSSEC should take a lesson from?
Having listed the “success” stories of ssh and tls, he than looks at DNSSEC. His first factual statement regarding DNSSEC is “Most resolving software supports DNSSEC, but none have enabled it by default“. He is wrong. I have been the package (co)maintainer of bind, unbound and nsd for Fedora and EPEL for many years. On Fedora and EPEL/RHEL the default install enables DNSSEC for all three, and has done so for many years – even before the root was signed with DNSSEC!
Next he claims “To enable DNSSEC we have a ‘tutorial’ by Olaf Kolkman which spans a whopping sixty-nine pages“. As I said, the author is wrong. Simply “yum install bind nsd unbound” and the software comes with dnssec enabled, using the root key as trust anchor.
He then points to a DNSSEC training that takes “multiple days” and claiming that shows the complexity. The same vendor lists a two day DHCP course, a two and a five day “plain DNS & bind” course, and a two and five day IPv6 course. Does that mean those technologies are all failures too because it takes so many days to teach a course about it? According to the author, DHCP would be a failure and no one can deploy it because it “requires” a two day training? It’s just simplistic cherry-picked FUD.
His next argument is “Furthermore, there are almost no simple instructions for enabling DNSSEC, especially none that use KSKs and ZSKs, and include instructions on how to do key rollovers.“.
First, let me ask you how you do an ssh host key rollover? How do you make that seamless so it won’t trigger anyone who ever connected before from seeing a changed key? Where do they go to confirm the changed key is installed by the administrator and not the result of a hacked server or connection? Does this mean ssh has failed too? Again, amusingly enough the only way to rollover ssh keys is piggybacking on SSHFP in DNSSEC or GSSAPI trust models. But I don’t see the author claiming ssh has failed because it cannot do rollovers on its own. More cherry-picking.
The reality is, ssh and DNSSEC can do fine without rollovers. Only TLS requires rollovers because the trust model depends on the fact that you regularly pay the trustees managing that whole disaster. But if you do want or need to do a rollover, with ssh you’re fucked, with TLS you have to pay and with DNSSEC you have a seamless transition method. Let me repeat that – only DNSSEC actually implements a free and seamless key rollover mechanism! So of course, the author just states it is too hard to use. But again does not compare it against TLS or ssh at all. Cherry-picking all the way down. And by the way, there are also good reasons why you do not need to worry about DNSSEC rollovers at all.
As I said before, DNSSEC is already “enabled”, so let’s interpret the author’s quest for “simple instructions to enable DNSSEC” to mean “how do I sign my zone?”. Let us assume he is running bind right now with his zone in /var/named/1sand0s.nl. The author now has to issue the following complicated sequence of commands:
$ dnssec-keygen -f KSK -a RSASHA256 -b 2048 -n ZONE 1sand0s.nl
Generating key pair........+++ ..+++
K1sand0s.nl.+008+01699
$ dnssec-keygen -a RSASHA256 -b 1024 -n ZONE 1sand0s.nl
Generating key pair........................................++++++ ..................++++++
K1sand0s.nl.+008+24363
$ cat K1sand0s.nl.*.key >> 1sand0s.nl
$ dnssec-signzone -o 1sand0s.nl -k K1sand0s.nl.+008+01699 1sand0s.nl K1sand0s.nl.+008+24363
Verifying the zone using the following algorithms: RSASHA256.
Zone fully signed:
Algorithm: RSASHA256: KSKs: 1 active, 0 stand-by, 0 revoked
ZSKs: 1 active, 0 stand-by, 0 revoked
1sand0s.nl.signed
Edit named.conf and load the file 1sand0s.nl.signed instead of 1sand0s.nl and you’re done. And whenever you change your zone, re-run that dnssec-signer command.
(NOTE: and as pointed out to me, if you don’t have zone edits every week, do run that signer command in a cron job weekly to refresh the DNSSEC signature records)
You can put this into a git hook and maintain the whole thing without ever realising there is a signing step in between. Hardly rocket science. I think we can argue whether or not this is harder or easier than creating a CSR for Apache, get it signed, and than installed (and too many people will forget to actually get the intermediate CAs installed in apache, and their deployment is actually even broken!)
The author’s issue with opendnssec is that it is “yet another daemon” using a “database backend”. I guess he is also not running postfix because that thing has more daemons than I can remember the names of. Opendnssec’s default “database backend” is sqlite. If you hate those, there is a lot of software you’ll going to have to purge from your servers. Sqlite is a perfect backend for small databases that are just too complex for simple text files. For those of us who don’t mind two extra daemons and some sqlite files, to sign your domain from scratch with opendnssec:
# yum install opendnssec
# systemctl enable opendnssec.service
# systemctl start opendnssec.service
# ods-ksmutil zone add –zone 1sand0s.nl –input /var/named/1sand0s.nl –output /var/named/1sand0s.nl.signed
# ods-signer sign 1sand0s.nl
Change named to load the .signed zone instead of the unsigned zone and done. Shockingly complicated! Unsuitable for “common engineers” according to the author.
To make these instructions complete, the last step is to send your DS record to your Registrar which involves using their custom webgui to send them the following data:
yum install ldns
dig dnskey 1sand0s.nl > 1sand0s.nl.dnskey
ldns-key2ds -n 1sand0s.nl.dnskey
And if you want to do all of this within the same bind daemon and without sqlite, you can use bind’s builtin inline-signing management features instead.
Conclusion
Saying the tools are there for ssh (which doesn’t have ANY rollover support) and tls (which over half the world has misconfigured regardless of rollovers) but not for dnssec, is really short-sighted and wrong. What the author has done is taken his prejudice, and written some cherry-picked text justifying it. The only credit I can give him, is that he did not have to rely on the FUD statements by djb.
{kind=link}